
Artificial Intelligence (AI) and Machine Learning (ML) have become the backbone of modern digital transformation, and so is the AWS Certified Machine Learning Engineer – Associate Exam. From predictive analytics to generative AI and automation, businesses across every sector are investing in machine learning to improve efficiency, enhance customer experiences, and unlock new insights. As this demand grows, so does the need for professionals who can not only understand ML concepts but also implement, deploy, and manage them effectively on cloud platforms.
To address this growing skill requirement, Amazon Web Services (AWS) has introduced the AWS Certified Machine Learning Engineer – Associate (MLA-C01) certification. This new associate-level credential is designed to validate your ability to build, train, deploy, and optimise machine learning models using AWS tools and services.
What is the AWS Certified Machine Learning Engineer – Associate Exam?
The AWS Certified Machine Learning Engineer – Associate (MLA-C01) exam is a recently introduced certification by Amazon Web Services that focuses on validating a professional’s ability to design, build, train, deploy, and optimise machine learning (ML) models using AWS technologies. Positioned between the AI Practitioner and the Machine Learning – Specialty certifications, it serves as a bridge between foundational AI understanding and advanced ML expertise.
This certification goes beyond theoretical concepts — it tests your hands-on ability to apply ML engineering principles in real-world, production-grade AWS environments. Candidates are expected to demonstrate knowledge of the end-to-end ML lifecycle, from data preparation and feature engineering to model evaluation, deployment, and monitoring.
At its core, the exam is designed for professionals who can transform business challenges into ML-driven solutions. You will need to understand how to use key AWS services such as:
- Amazon SageMaker for model development, training, and deployment.
- AWS Glue and Amazon S3 for data ingestion and preprocessing.
- Amazon Bedrock for generative AI applications.
- Amazon Comprehend, Rekognition, and Lex for NLP, computer vision, and conversational AI tasks.
The certification also assesses your familiarity with MLOps practices, which combine machine learning with DevOps principles to automate deployment pipelines, ensure reliability, and manage scalability in production.
In simple terms, this exam is meant for individuals who already have a grasp of machine learning theory and now want to demonstrate their practical ability to implement ML workflows on AWS. It recognises engineers who can efficiently deploy, maintain, and optimise AI systems — skills that are becoming essential as organisations move from experimentation to large-scale AI adoption.
Who should take this Certification?
The AWS Certified Machine Learning Engineer – Associate (MLE-A) certification is tailored for professionals who are actively involved in building, deploying, and maintaining machine learning (ML) models in production environments. It is best suited for those who already have a foundational understanding of AI and cloud computing and are now ready to demonstrate hands-on proficiency in applied ML engineering using AWS tools.
This certification bridges the gap between conceptual AI knowledge and real-world implementation, making it a strong choice for individuals who want to validate their technical expertise and career readiness in the fast-growing field of AI and ML operations.
Here are the key profiles that will benefit most from pursuing this certification:
- Machine Learning Engineers: Professionals responsible for designing, training, and deploying machine learning models in production. The certification confirms your ability to use AWS services like SageMaker and Bedrock to scale ML workflows efficiently.
- Data Scientists and Analysts: If you already work with data and want to take the next step into applied ML engineering, this certification helps you master the deployment, automation, and optimization side of machine learning.
- Software and Cloud Developers: Developers who integrate AI and ML functionalities into their applications can benefit from understanding AWS’s managed ML services. This certification helps them build intelligent, cloud-native applications faster and with greater reliability.
- MLOps and DevOps Engineers: For those specialising in automation and continuous integration, this certification provides a deep dive into how ML pipelines can be integrated into CI/CD workflows, ensuring seamless deployment and monitoring of models in production.
- AI and Cloud Enthusiasts or Students: Aspiring professionals who want to move beyond theory into practical ML implementation on AWS will find this certification an excellent foundation for a career in AI engineering.
- Professionals Targeting the Machine Learning – Specialty Exam: The MLE-A certification serves as a stepping stone for the more advanced AWS Certified Machine Learning – Specialty credential. It allows you to gain hands-on experience before tackling complex model optimisation and algorithmic design challenges.
In essence, if your goal is to prove your ability to operationalise machine learning — not just understand it — this certification is a strong fit. It highlights your readiness to manage real-world ML pipelines and contribute meaningfully to AI innovation in enterprise cloud environments.
Understanding the Exam Structure
The AWS Certified Machine Learning Engineer – Associate (MLA-C01) exam is designed to assess your ability to apply end-to-end machine learning (ML) engineering practices using AWS tools and services. It focuses on both conceptual understanding and practical implementation, ensuring that you can design, train, deploy, and optimise ML models in real-world production environments.
Here are the key details of the exam:
- Number of Questions: 85
- Duration: 170 minutes
- Languages Available: English, Japanese
- Passing Score: 720 (on a scale of 100–1000)
The exam uses a multiple-choice and multiple-response format, testing your ability to make decisions across various stages of the ML workflow. Many questions are scenario-based, requiring you to analyse a given problem and determine the most efficient AWS solution or workflow to apply.
Core Exam Domains
Domain 1: Data Preparation for Machine Learning (ML)
Task Statement 1.1: Ingest and store data.
Knowledge of:
- Data formats and ingestion mechanisms (for example, validated and non-validated formats, Apache Parquet, JSON, CSV, Apache ORC, Apache Avro, RecordIO)
- How to use the core AWS data sources (for example, Amazon S3, Amazon Elastic File System [Amazon EFS], Amazon FSx for NetApp ONTAP)
- How to use AWS streaming data sources to ingest data (for example, Amazon Kinesis, Apache Flink, Apache Kafka)
- AWS storage options, including use cases and tradeoffs
Skills in:
- Extracting data from storage (for example, Amazon S3, Amazon Elastic Block Store [Amazon EBS], Amazon EFS, Amazon RDS, Amazon DynamoDB) by using relevant AWS service options (for example, Amazon S3 Transfer Acceleration, Amazon EBS Provisioned IOPS)
- Choosing appropriate data formats (for example, Parquet, JSON, CSV, ORC) based on data access patterns
- Ingesting data into Amazon SageMaker Data Wrangler and SageMaker Feature Store
- Merging data from multiple sources (for example, by using programming techniques, AWS Glue, Apache Spark)
- Troubleshooting and debugging data ingestion and storage issues that involve capacity and scalability
- Making initial storage decisions based on cost, performance, and data structure
Task Statement 1.2: Transform data and perform feature engineering.
Knowledge of:
- Data cleaning and transformation techniques (for example, detecting and treating outliers, imputing missing data, combining, deduplication)
- Feature engineering techniques (for example, data scaling and standardization, feature splitting, binning, log transformation, normalization)
- Encoding techniques (for example, one-hot encoding, binary encoding, label encoding, tokenization)
- Tools to explore, visualize, or transform data and features (for example, SageMaker Data Wrangler, AWS Glue, AWS Glue DataBrew)
- Services that transform streaming data (for example, AWS Lambda, Spark)
- Data annotation and labeling services that create high-quality labeled datasets
Skills in:
- Transforming data by using AWS tools (for example, AWS Glue, AWS Glue DataBrew, Spark running on Amazon EMR, SageMaker Data Wrangler)
- Creating and managing features by using AWS tools (for example, SageMaker Feature Store)
- Validating and labeling data by using AWS services (for example, SageMaker Ground Truth, Amazon Mechanical Turk)
Task Statement 1.3: Ensure data integrity and prepare data for modeling.
Knowledge of:
- Pre-training bias metrics for numeric, text, and image data (for example, class imbalance [CI], difference in proportions of labels [DPL])
- Strategies to address CI in numeric, text, and image datasets (for example, synthetic data generation, resampling)
- Techniques to encrypt data
- Data classification, anonymization, and masking
- Implications of compliance requirements (for example, personally identifiable information [PII], protected health information [PHI], data residency)
Skills in:
- Validating data quality (for example, by using AWS Glue DataBrew and AWS Glue Data Quality)
- Identifying and mitigating sources of bias in data (for example, selection bias, measurement bias) by using AWS tools (for example, SageMaker Clarify)
- Preparing data to reduce prediction bias (for example, by using dataset splitting, shuffling, and augmentation)
- Configuring data to load into the model training resource (for example, Amazon EFS, Amazon FSx)
Domain 2: ML Model Development
Task Statement 2.1: Choose a modeling approach.
Knowledge of:
- Capabilities and appropriate uses of ML algorithms to solve business problems
- How to use AWS artificial intelligence (AI) services (for example, Amazon Translate, Amazon Transcribe, Amazon Rekognition, Amazon Bedrock) to solve specific business problems
- How to consider interpretability during model selection or algorithm selection
- SageMaker built-in algorithms and when to apply them
Skills in:
- Assessing available data and problem complexity to determine the feasibility of an ML solution
- Comparing and selecting appropriate ML models or algorithms to solve specific problems
- Choosing built-in algorithms, foundation models, and solution templates (for example, in SageMaker JumpStart and Amazon Bedrock)
- Selecting models or algorithms based on costs
- Selecting AI services to solve common business needs
Task Statement 2.2: Train and refine models.
Knowledge of:
- Elements in the training process (for example, epoch, steps, batch size)
- Methods to reduce model training time (for example, early stopping, distributed training)
- Factors that influence model size
- Methods to improve model performance
- Benefits of regularization techniques (for example, dropout, weight decay, L1 and L2)
- Hyperparameter tuning techniques (for example, random search, Bayesian optimization)
- Model hyperparameters and their effects on model performance (for example, number of trees in a tree-based model, number of layers in a neural network)
- Methods to integrate models that were built outside SageMaker into SageMaker
Skills in:
- Using SageMaker built-in algorithms and common ML libraries to develop ML models
- Using SageMaker script mode with SageMaker supported frameworks to train models (for example, TensorFlow, PyTorch)
- Using custom datasets to fine-tune pre-trained models (for example, Amazon Bedrock, SageMaker JumpStart)
- Performing hyperparameter tuning (for example, by using SageMaker automatic model tuning [AMT])
- Integrating automated hyperparameter optimization capabilities
- Preventing model overfitting, underfitting, and catastrophic forgetting (for example, by using regularization techniques, feature selection)
- Combining multiple training models to improve performance (for example, ensembling, stacking, boosting)
- Reducing model size (for example, by altering data types, pruning, updating feature selection, compression)
- Managing model versions for repeatability and audits (for example, by using the SageMaker Model Registry)
Task Statement 2.3: Analyze model performance.
Knowledge of:
- Model evaluation techniques and metrics (for example, confusion matrix, heat maps, F1 score, accuracy, precision, recall, Root Mean Square Error [RMSE], receiver operating characteristic [ROC], Area Under the ROC Curve [AUC])
- Methods to create performance baselines
- Methods to identify model overfitting and underfitting
- Metrics available in SageMaker Clarify to gain insights into ML training data and models
- Convergence issues
Skills in:
- Selecting and interpreting evaluation metrics and detecting model bias
- Assessing tradeoffs between model performance, training time, and cost
- Performing reproducible experiments by using AWS services
- Comparing the performance of a shadow variant to the performance of a production variant
- Using SageMaker Clarify to interpret model outputs
- Using SageMaker Model Debugger to debug model convergence
Domain 3: Deployment and Orchestration of ML Workflows
Task Statement 3.1: Select deployment infrastructure based on existing architecture and requirements.
Knowledge of:
- Deployment best practices (for example, versioning, rollback strategies)
- AWS deployment services (for example, SageMaker)
- Methods to serve ML models in real time and in batches
- How to provision compute resources in production environments and test environments (for example, CPU, GPU)
- Model and endpoint requirements for deployment endpoints (for example, serverless endpoints, real-time endpoints, asynchronous endpoints, batch inference)
- How to choose appropriate containers (for example, provided or customized)
- Methods to optimize models on edge devices (for example, SageMaker Neo)
Skills in:
- Evaluating performance, cost, and latency tradeoffs
- Choosing the appropriate compute environment for training and inference based on requirements (for example, GPU or CPU specifications, processor family, networking bandwidth)
- Selecting the correct deployment orchestrator (for example, Apache Airflow, SageMaker Pipelines)
- Selecting multi-model or multi-container deployments
- Selecting the correct deployment target (for example, SageMaker endpoints, Kubernetes, Amazon Elastic Container Service [Amazon ECS], Amazon Elastic Kubernetes Service [Amazon EKS], Lambda)
- Choosing model deployment strategies (for example, real time, batch)
Task Statement 3.2: Create and script infrastructure based on existing architecture and requirements.
Knowledge of:
- Difference between on-demand and provisioned resources
- How to compare scaling policies
- Tradeoffs and use cases of infrastructure as code (IaC) options (for example, AWS CloudFormation, AWS Cloud Development Kit [AWS CDK])
- Containerization concepts and AWS container services
- How to use SageMaker endpoint auto scaling policies to meet scalability requirements (for example, based on demand, time)
Skills in:
- Applying best practices to enable maintainable, scalable, and cost-effective ML solutions (for example, automatic scaling on SageMaker endpoints, dynamically adding Spot Instances, by using Amazon EC2 instances, by using Lambda behind the endpoints)
- Automating the provisioning of compute resources, including communication between stacks (for example, by using CloudFormation, AWS CDK)
- Building and maintaining containers (for example, Amazon Elastic Container Registry [Amazon ECR], Amazon EKS, Amazon ECS, by using bring your own container [BYOC] with SageMaker)
- Configuring SageMaker endpoints within the VPC network
- Deploying and hosting models by using the SageMaker SDK
- Choosing specific metrics for auto scaling (for example, model latency, CPU utilization, invocations per instance)
Task Statement 3.3: Use automated orchestration tools to set up continuous integration and continuous delivery (CI/CD) pipelines.
Knowledge of:
- Capabilities and quotas for AWS CodePipeline, AWS CodeBuild, and AWS CodeDeploy
- Automation and integration of data ingestion with orchestration services
- Version control systems and basic usage (for example, Git)
- CI/CD principles and how they fit into ML workflows
- Deployment strategies and rollback actions (for example, blue/green, canary, linear)
- How code repositories and pipelines work together
Skills in:
- Configuring and troubleshooting CodeBuild, CodeDeploy, and CodePipeline, including stages
- Applying continuous deployment flow structures to invoke pipelines (for example, Gitflow, GitHub Flow)
- Using AWS services to automate orchestration (for example, to deploy ML models, automate model building)
- Configuring training and inference jobs (for example, by using Amazon EventBridge rules, SageMaker Pipelines, CodePipeline)
- Creating automated tests in CI/CD pipelines (for example, integration tests, unit tests, end-to-end tests)
- Building and integrating mechanisms to retrain models
Domain 4: ML Solution Monitoring, Maintenance, and Security
Task Statement 4.1: Monitor model inference.
Knowledge of:
- Drift in ML models
- Techniques to monitor data quality and model performance
- Design principles for ML lenses relevant to monitoring
Skills in:
- Monitoring models in production (for example, by using SageMaker Model Monitor)
- Monitoring workflows to detect anomalies or errors in data processing or model inference
- Detecting changes in the distribution of data that can affect model performance (for example, by using SageMaker Clarify)
- Monitoring model performance in production by using A/B testing
Task Statement 4.2: Monitor and optimize infrastructure and costs.
Knowledge of:
- Key performance metrics for ML infrastructure (for example, utilization, throughput, availability, scalability, fault tolerance)
- Monitoring and observability tools to troubleshoot latency and performance issues (for example, AWS X-Ray, Amazon CloudWatch Lambda Insights, Amazon CloudWatch Logs Insights)
- How to use AWS CloudTrail to log, monitor, and invoke re-training activities
- Differences between instance types and how they affect performance (for example, memory optimized, compute optimized, general purpose, inference optimized)
- Capabilities of cost analysis tools (for example, AWS Cost Explorer, AWS Billing and Cost Management, AWS Trusted Advisor)
- Cost tracking and allocation techniques (for example, resource tagging)
Skills in:
- Configuring and using tools to troubleshoot and analyze resources (for example, CloudWatch Logs, CloudWatch alarms)
- Creating CloudTrail trails
- Setting up dashboards to monitor performance metrics (for example, by using Amazon QuickSight, CloudWatch dashboards)
- Monitoring infrastructure (for example, by using EventBridge events)
- Rightsizing instance families and sizes (for example, by using SageMaker Inference Recommender and AWS Compute Optimizer)
- Monitoring and resolving latency and scaling issues
- Preparing infrastructure for cost monitoring (for example, by applying a tagging strategy)
- Troubleshooting capacity concerns that involve cost and performance (for example, provisioned concurrency, service quotas, auto scaling)
- Optimizing costs and setting cost quotas by using appropriate cost management tools (for example, AWS Cost Explorer, AWS Trusted Advisor, AWS Budgets)
- Optimizing infrastructure costs by selecting purchasing options (for example, Spot Instances, On-Demand Instances, Reserved Instances, SageMaker Savings Plans)
Task Statement 4.3: Secure AWS resources.
Knowledge of:
- IAM roles, policies, and groups that control access to AWS services (for example, AWS Identity and Access Management [IAM], bucket policies, SageMaker Role Manager)
- SageMaker security and compliance features
- Controls for network access to ML resources
- Security best practices for CI/CD pipelines
Skills in:
- Configuring least privilege access to ML artifacts
- Configuring IAM policies and roles for users and applications that interact with ML systems
- Monitoring, auditing, and logging ML systems to ensure continued security and compliance
- Troubleshooting and debugging security issues
- Building VPCs, subnets, and security groups to securely isolate ML systems
Skills Validated by the Certification
The AWS Certified Machine Learning Engineer – Associate (MLA-C01) certification validates a professional’s ability to apply practical, end-to-end machine learning (ML) engineering skills within the AWS ecosystem. It confirms that you not only understand the concepts of AI and ML but can also build, deploy, and manage production-level models using AWS tools and frameworks.
This certification assesses your competence across four key skill areas that define a modern ML engineer’s role.
1. Data Preparation and Feature Engineering
The certification validates your ability to collect, clean, and transform raw data into model-ready datasets. You are expected to:
- Use AWS Glue, Data Wrangler, and Amazon S3 for data ingestion and preprocessing.
- Handle missing values, outliers, and scaling issues effectively.
- Engineer relevant features that improve model performance.
- Understand dataset partitioning, labelling, and transformation workflows.
2. Model Building, Training, and Evaluation
You will be tested on your ability to design and train efficient ML models using AWS services such as Amazon SageMaker. Key skills include:
- Choosing appropriate algorithms for regression, classification, NLP, or computer vision tasks.
- Performing hyperparameter tuning and model optimisation.
- Evaluating model performance using metrics like accuracy, precision, recall, and AUC.
- Managing training infrastructure, cost, and resource scalability on AWS.
3. Model Deployment and Automation (MLOps)
This certification ensures you can operationalise models for real-world use cases. You will need to:
- Deploy models using SageMaker Endpoints and Batch Transform.
- Implement CI/CD pipelines using SageMaker Pipelines, AWS CodePipeline, or Lambda.
- Automate model retraining and version control.
- Understand containerisation (Docker/ECR) for scalable ML deployment.
4. Model Monitoring, Optimisation, and Troubleshooting
The MLE-A certification also validates your ability to maintain and optimise ML models post-deployment. Skills tested include:
- Monitoring drift, bias, and latency using SageMaker Model Monitor and CloudWatch.
- Applying feedback loops to improve performance.
- Troubleshooting errors in model prediction and resource utilisation.
- Managing security, compliance, and governance across ML systems.
5. Applied Understanding of AWS AI Services
Beyond model development, the certification ensures familiarity with pre-trained AWS AI services, such as:
- Amazon Comprehend for natural language processing.
- Amazon Rekognition for computer vision.
- Amazon Bedrock for generative AI applications.
- Amazon Lex and Transcribe for conversational AI and speech recognition.
In essence, this certification proves that you can build and operationalise ML solutions that are scalable, cost-efficient, and production-ready. It signifies your readiness to handle complex AI workloads and collaborate effectively with data, engineering, and DevOps teams in enterprise environments.
Why is this Certification Important?
The AWS Certified Machine Learning Engineer – Associate (MLA-C01) certification is a milestone credential for professionals who want to demonstrate practical expertise in deploying and managing machine learning (ML) models at scale. In today’s cloud-first world, where AI and ML are embedded into nearly every business process, this certification provides a clear validation of your ability to bridge the gap between data science, engineering, and cloud operations.
Here are the key reasons why this certification holds significant value:
1. Addresses the Industry’s Demand for Applied ML Skills
While many professionals understand the theory behind machine learning, far fewer can implement ML models in production environments. This certification focuses specifically on those real-world skills — from data preparation to model monitoring — that employers need most. It proves you can operationalise AI solutions, not just conceptualise them.
2. Builds Expertise in End-to-End Machine Learning Lifecycle
Unlike purely theoretical exams, the MLE-A certification tests your ability to manage every stage of an ML project:
- Preparing and cleaning data.
- Selecting the right algorithms.
- Training and optimising models.
- Deploying and maintaining them securely on AWS.
This makes it one of the most holistic and hands-on ML certifications available at the associate level.
3. Strengthens Your Cloud and AI Integration Skills
Machine learning is increasingly dependent on cloud platforms for scalability, storage, and automation. By mastering AWS ML services like SageMaker, Glue, and Bedrock, you gain the ability to design solutions that are both technically efficient and cost-effective — a key advantage in enterprise environments.
4. Establishes You as an AWS AI Specialist
AWS is one of the most widely used cloud providers globally. Earning this certification signals to employers that you have mastered AWS’s ML ecosystem and can apply its services to real business challenges. It also enhances your credibility for roles involving MLOps, AI engineering, and cloud-based model deployment.
5. Serves as a Bridge to Advanced AWS Certifications
For professionals aiming to specialise further, the MLE-A serves as a strategic stepping stone toward the AWS Certified Machine Learning – Specialty certification. It ensures that you have a strong applied foundation before progressing into advanced areas like deep learning, neural networks, and custom model development.
6. High Career and Salary Potential
With companies accelerating their AI adoption, certified ML engineers are in high demand. This certification can lead to roles such as Machine Learning Engineer, MLOps Specialist, AI Solutions Architect, or Cloud AI Developer, all of which command competitive salaries across global markets.
7. Future-Proofing Your Career in the Age of Generative AI
As AWS expands its AI offerings through services like Amazon Bedrock, having this certification places you at the forefront of the generative AI revolution. It ensures you are not only familiar with traditional ML workflows but also ready to work with the next generation of intelligent, large-scale AI systems.
In summary, the AWS Certified Machine Learning Engineer – Associate certification is important because it validates real, applicable expertise — the kind that transforms AI from theory into production-ready systems. It signals to employers that you can be trusted to handle the technical and operational demands of modern machine learning.
Career Opportunities after passing the AWS Certified Machine Learning Engineer – Associate Exam
Earning the AWS Certified Machine Learning Engineer – Associate (MLA-C01) certification can significantly enhance your career prospects in the fast-growing field of artificial intelligence and cloud computing. As organisations increasingly move from experimenting with AI to deploying production-grade machine learning (ML) models, the demand for professionals who can operationalise these solutions on cloud platforms like AWS is at an all-time high.
This certification signals to employers that you possess both the technical depth and practical experience needed to manage the entire ML lifecycle — from data processing to model deployment and monitoring. It positions you as a skilled engineer capable of translating AI concepts into scalable, real-world applications.
Top Career Roles You Can Pursue
- Machine Learning Engineer
Design, train, and deploy ML models that power predictive analytics, recommendation systems, and automation workflows on AWS. - MLOps Engineer
Build and manage CI/CD pipelines for ML workflows, ensuring automation, scalability, and reliability of production models. - AI/ML Developer
Integrate machine learning capabilities into web, mobile, or enterprise applications using AWS AI services such as Bedrock, Comprehend, and Rekognition. - Applied Data Scientist
Collaborate with engineering teams to deploy and optimise ML models that turn data insights into business value. - AI Solutions Architect
Design cloud-based AI and ML infrastructures that align with enterprise needs for scalability, cost-efficiency, and compliance. - Cloud Engineer (AI and Data Focus)
Oversee the implementation of AI workloads, manage data pipelines, and integrate ML systems into broader AWS cloud operations.
Career Growth Path
The MLE-A certification opens up multiple progression routes depending on your goals and background:
- For data professionals, it serves as a launchpad toward roles in machine learning and AI development.
- For software engineers, it bridges the gap between traditional coding and intelligent system design.
- For cloud administrators and DevOps engineers, it extends your expertise into MLOps and AI automation.
You can also advance to more specialised credentials such as:
- AWS Certified Machine Learning – Specialty
- AWS Certified Data Engineer – Associate
- AWS Certified AI Practitioner (for foundational reinforcement)
Salary Expectations
Professionals with this certification can command high salaries due to their ability to operationalise complex AI solutions. While exact compensation varies by experience and region, certified ML engineers consistently rank among the top-paid cloud professionals globally.
| Role | Average Salary (India) | Average Salary (Global) |
|---|---|---|
| Machine Learning Engineer | ₹12–24 LPA | $115,000–135,000 |
| MLOps Engineer | ₹13–26 LPA | $120,000–145,000 |
| AI Developer | ₹9–18 LPA | $95,000–120,000 |
| Applied Data Scientist | ₹10–22 LPA | $110,000–130,000 |
| AI Solutions Architect | ₹15–28 LPA | $125,000–150,000 |
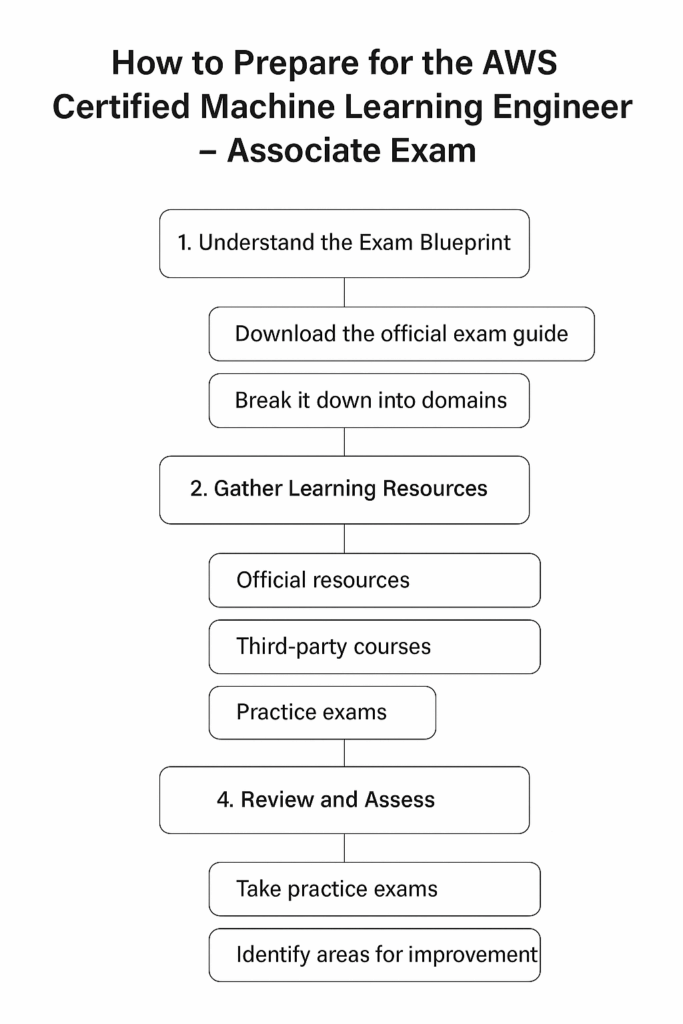
How to Prepare for the AWS Certified Machine Learning Engineer – Associate Exam?
- Step 1: Know the Exam Blueprint
- The exam is divided into domains like Data Engineering, Exploratory Data Analysis, Modeling, and Machine Learning Implementation & Operations.
- Each domain has a percentage weight, so you should prioritize your effort accordingly.
- Print the exam guide and keep it as your checklist.
- Step 2: Build Strong Foundations
- Review ML basics (supervised, unsupervised, deep learning, NLP) before diving into AWS services.
- Understand key AWS services like SageMaker, S3, Lambda, API Gateway, and CloudWatch.
- Step 3: Balance Theory and Hands-on Practice
- Reading about services is not enough. Deploy ML models in SageMaker, set up pipelines, use feature stores, and test MLOps workflows.
- AWS loves scenario-based questions, so practice real-world setups.
- Step 4: Practice, Review, Repeat
- Take practice exams at least twice before the real test.
- Use wrong answers to guide deeper study.
Recommended Learning Resources
Official AWS Resources
- Exam Guide & Sample Questions: AWS Exam Guide
- AWS Training: “Machine Learning Engineer – Associate Official Practice Question Set”
- AWS Whitepapers & FAQs:
- ML Lens of AWS Well-Architected Framework
- Amazon SageMaker FAQs
- Security best practices on AWS
Hands-On Resources
- AWS Free Tier & SageMaker Studio Lab (free GPU/CPU environments to practice).
- AWS Workshops: Search for ML & SageMaker workshops.
Practice Tests & Labs
- Prepare with the latest and updated practice exam and learning guide
AWS Certified Machine Learning Engineer Study Plan
| Week | Focus Area | Topics to Cover | Hands-On / Practice | Resources |
|---|---|---|---|---|
| 1 | Kickoff & Foundations | – Read exam guide – ML basics: regression, classification, clustering, DL intro | – Set up AWS Free Tier & SageMaker Studio Lab – Run a basic notebook | – Exam Guide – Coursera ML intro – AWS ML Foundations |
| 2 | Data Engineering (Domain 1) | – S3, Glue, Redshift, Kinesis – Data ingestion & transformation – Data Wrangler | – Clean & prepare datasets in SageMaker – Try Glue ETL job | – AWS Big Data whitepaper – SageMaker Data Wrangler docs |
| 3 | Exploratory Data Analysis (Domain 2) | – Feature engineering – Normalization, missing values – Handling imbalance | – Create features in SageMaker Feature Store – Try EDA on sample dataset | – SageMaker Feature Store tutorials |
| 4 | Modeling (Domain 3 – Part 1) | – SageMaker built-in algorithms – Custom models – AutoPilot | – Train a classification model in SageMaker – Hyperparameter tuning job | – SageMaker training docs – AWS Labs on GitHub |
| 5 | Modeling (Domain 3 – Part 2) | – Deep learning (TensorFlow, PyTorch) – Distributed training – Spot/GPU usage | – Deploy sentiment analysis model – Try distributed training job | – SageMaker DL framework guides |
| 6 | ML Implementation & Ops (Domain 4 – Part 1) | – MLOps concepts – CI/CD for ML – Pipelines | – Build a SageMaker pipeline – Automate training | – AWS MLOps whitepaper – SageMaker Pipelines tutorial |
| 7 | ML Implementation & Ops (Domain 4 – Part 2) | – Deployment strategies – Batch transform, multi-model endpoints – Monitoring & drift detection | – Deploy endpoint – Enable monitoring & alerts | – SageMaker deployment docs |
| 8 | Security, Governance & Optimization | – IAM roles for ML – Data encryption – Cost optimization | – Test IAM roles – Enable CloudWatch for ML jobs | – AWS Security Best Practices – Cost optimization guide |
| 9 | Practice & Weak Areas | – Full-length practice test – Identify weak domains – Revisit whitepapers | – Re-do labs in weak areas – Retry failed practice Qs | – Tutorials Dojo / Jon Bonso practice exams |
| 10 | Final Review & Exam Readiness | – Mock exams under time – Skim whitepapers & FAQs – Review cheat sheets | – 2–3 timed mock exams – Rest before exam day | – AWS FAQs – Practice test providers |
Conclusion
The AWS Certified Machine Learning Engineer – Associate (MLA-C01) certification represents a major step forward for professionals aiming to master the real-world application of machine learning within the AWS cloud ecosystem. Unlike entry-level credentials that focus on AI theory, this certification validates your ability to engineer, deploy, and manage production-ready ML models — a skill set that sits at the intersection of data science, software engineering, and cloud architecture.
It empowers you to take ownership of the entire machine learning lifecycle, from data preparation to monitoring deployed models. By proving your ability to operationalise ML pipelines using tools such as Amazon SageMaker, Glue, and Bedrock, you become a key contributor to any organisation’s AI transformation journey.
As machine learning continues to define the future of automation, analytics, and innovation, AWS-certified ML engineers are emerging as some of the most in-demand professionals in the global job market. This certification not only validates your technical expertise but also demonstrates your readiness to build scalable, secure, and high-performing AI systems in production environments.



